この記事は、ニフクラブログで2022-02-02に公開された記事を移転したものです。
こんにちは、CRE部 技術支援チームです。
今回はいつもの検証から離れて、Linuxのディスク回りの挙動についてお話します。
本記事では、ニフクラ障害時に発生する可能性のあるファイルシステムのリードオンリー化発生についてのロジックと、回避するための情報を提要します。
ただし、回避することが最適な対応策であるとは限りません。回避策を適用される場合は本文を最後までお読みいただき、リスクを理解した上で適用をご検討ください。
また、理解を優先とするため、一部情報や用語について省略して表記しておりますことをご了承ください。
前提条件
本ブログは、以下の前提知識がある方を想定とします。
- Linuxサーバーの基本的な操作、知識
- Linuxカーネルパラメータの基本的な操作、知識
背景
仮想マシンで発生するファイルシステムのリードオンリー化について
VMware製品による仮想環境では、仮想環境特有のディスクタイムアウト設定を実施*1する必要があります。
VMware vSphereを基盤とするニフクラでも、OS上に導入されているopen-vmware-toolsによりudevルール*2が設定されているため、上記ディスクタイムアウト値の設定は実施済みです。
しかし、めったに無いことではありますが、IaaS基盤の障害が長期に及んだり、基盤障害と仮想マシンのIOタイミングの組み合わせにより、ディスクへのアクセスが失敗しファイルシステムがリードオンリーになることがあります。
そのような状態になる確立を下げる方法についてご紹介します。
リードオンリー化のメカニズム紹介
まずは、なぜLinuxのファイルシステムがリードオンリーになるのかを説明します。
流れが複雑なため、「ディスクアクセスタイムアウト発生の流れ」と、「ファイルシステムがリードオンリーになる流れ」の2段階に分けて説明します。
ディスクアクセスタイムアウト発生の流れ
LinuxのIOスタックを簡易に図示すると下記のようになります。
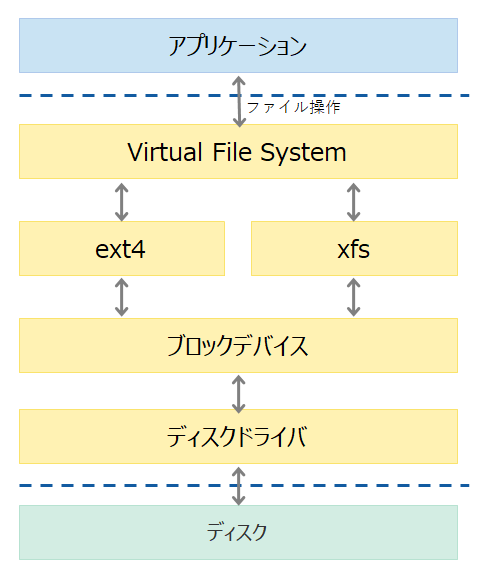
基盤障害でディスクへのアクセスに支障が生じると、下記のような動作となります

- ディスクへのアクセスが遮断される
- ファイルシステム層からブロック・デバイス層へのアクセス要求が発生
- ブロック・デバイス層にて、ディスクアクセスを実施
- Linuxカーネルパラメータに設定されたタイムアウトまで応答を待つ
タイムアウト回数がリトライ規定回数以下の場合、3に戻る - リトライ回数が規定値に達した場合、ブロックデバイスへのアクセス失敗をブロックデバイス層からファイルシステム層に通知
上記のような流れにより、ディスクへのアクセス失敗が発生します。
ディスクアクセスが失敗したときのファイルシステムからの要求が「特定のリクエスト」だった場合、ファイルシステムがリードオンリー化されます。
つづいて、この「特定のリクエスト」について説明します。
ファイルシステムがリードオンリーになる流れ
ext4、xfsファイルシステムは大きく分けて以下二つのデータを書き込みます。
- ジャーナル
ファイルシステム破損時に、ファイルシステムを迅速に正常化するためのログ情報 - 実データ(データ、更新日付などのメタデータ)
データそのものおよび、その付属情報
また、ファイルシステムへのデータ書き込みは下記のような流れで実施されます。
- オンメモリのジャーナルへ、ファイルシステムへの変更情報を記録(ジャーナル情報はバックグラウンドで定期的にディスクに書き出しされます)
- 実データの書き込みを実施
- 更新完了したら、ジャーナルに書き込んだ変更情報を削除
この流れを踏むことで、突然の障害発生時にディスク上のデータ整合性確認を迅速に完了させることが出来ます。
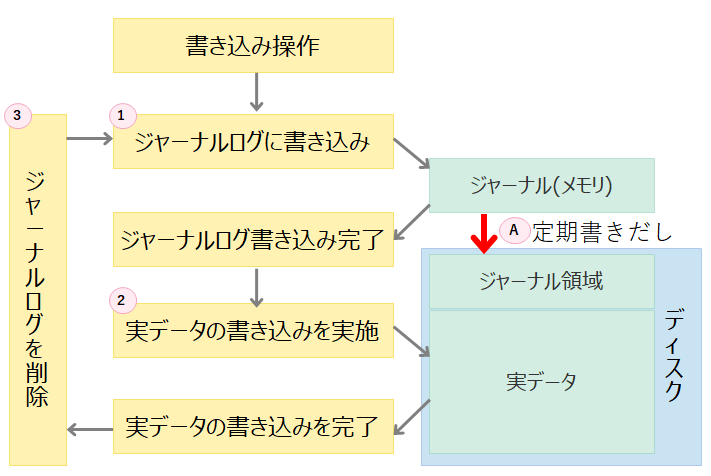
ここで、キーとなるのはジャーナルのディスクへの定期書きだし(図中のA)です。
図中の(A)、ジャーナルのディスクへの書き出しが、先に「ディスクアクセスタイムアウト発生の流れ」で述べた「特定のリクエスト」にあたります。
ジャーナルのディスクへの書き出しが失敗すると、実データとジャーナルの不整合が発生するためにファイルシステムを安全な状態に保てなくなるため、OSとしてデータ保護のために、ファイルシステムをリードオンリー化する流れとなります。
リードオンリーになる確率を下げる方法
上記ロジックを踏まえると、リードオンリーになる確率を下げるには、以下施策が考えられます。
- ディスクへのリトライ回数を増やす
- ディスクへのタイムアウト値を長くする
1については、Linuxのソースレベルで5回とハードコーティングされていますので、変更のハードルは非常に高いです。
一方、2に関してはLinuxのカーネルパラメータの設定変更により可能なため、比較的簡単に変更できます。 今回はこちらの方法をご紹介します。
ディスクタイムアウト値を一時的に変更する場合
sdbのディスクについてタイムアウト値を300秒に変更するサンプルは、以下となります。
ただし、実際は300秒のタイムアウトを5回繰り返すため、初回のリトライを合わせて6回、300*6=1,800秒がタイムアウト値となります。
echo 300 > /sys/block/sdb/device/timeout
上記対応で設定した値については、再起動やudevルール再適用時に変更されますので、本番運用時には下記方式をおすすめします。
ディスクタイムアウト値を恒久的に変更する場合
ディスクタイムアウト値を恒久的に変更する場合はudevルールを変更することで対応します。
例として、300秒にするときの対応手順は下記となります。
vmware-toolsでインストールされたudevルールを確認する
# ls /usr/lib/udev/rules.d/99-vmware-scsi-udev.rules /usr/lib/udev/rules.d/99-vmware-scsi-udev.rulesudevのルールを修正
viなどでファイルを開き、既存のルールのパラメータを変更します。
修正前
ACTION=="add", SUBSYSTEMS=="scsi", ATTRS{vendor}=="VMware*", ATTRS{model}=="Virtual disk*", ENV{DEVTYPE}=="disk", RUN+="/bin/sh -c 'echo 180 >/sys$env{DEVPATH}/device/timeout'" ACTION=="add", SUBSYSTEMS=="scsi", ATTRS{vendor}=="VMware*", ATTRS{model}=="VMware Virtual S", ENV{DEVTYPE}=="disk", RUN+="/bin/sh -c 'echo 180 >/sys$env{DEVPATH}/device/timeout'"修正後
ACTION=="add", SUBSYSTEMS=="scsi", ATTRS{vendor}=="VMware*", ATTRS{model}=="Virtual disk*", ENV{DEVTYPE}=="disk", RUN+="/bin/sh -c 'echo 300 >/sys$env{DEVPATH}/device/timeout'" ACTION=="add", SUBSYSTEMS=="scsi", ATTRS{vendor}=="VMware*", ATTRS{model}=="VMware Virtual S", ENV{DEVTYPE}=="disk", RUN+="/bin/sh -c 'echo 300 >/sys$env{DEVPATH}/device/timeout'"適用前の値確認
現状の設定を確認します。
# cat /sys/block/sdb/device/timeout 180設定反映
udevルールを再実行して、値を反映させます。
# udevadm trigger --action=add適用後の値確認
無事適用されたか確認します。
# cat /sys/block/sdb/device/timeout 300これにてディスクタイムアウト値の変更は完了となります。
注意点
ここまでの対応で、リードオンリーになる確率を下げることができました。
ただし、注意点として、本対策によりディスクへの書き込みがメモリ上に滞留しやすくなることになるため下記のような注意点があります。
- ディスクへのアクセスができない状況でサーバ再起動が発生すると、データロストが発生する
- 新規プロセス生成のためのIOが滞留するため、OOM Killerが発生し、重要プロセスが落ちることがある
- IOできない状態のため、プロセスがハングアップしたログが120秒間隔で出続ける
- ディスクIOのタイムアウトを検知して動作するような処理がうまく動かなくなる(クラスタ切り替えなど)
- その他、ディスクIOが長時間滞留することを起因とした様々な問題
上記の課題は一例となりますので、実際の環境への適用はご自身の責任にて検証を実施し、適用をご検討ください。
まとめ
今回はLinuxのIO処理の詳細に触れつつ、ファイルシステムのリードオンリー化対策を解説しました。
めったにないことですが、ディスクアクセス不可を起因としたファイルシステムのリードオンリー化を回避したいとお考えの方は本対策の実施についてご検討ください。
今回は300秒としましたが、ご自身の運用に合わせて、もっと長い時間に設定してください。
また、運悪くファイルシステムがリードオンリーになってしまった場合は下記QAを参考に対策を実施ください。
- リードオンリー化しているかどうかの確認方法
https://faq.support.nifcloud.com/faq/show/283 - リードオンリー化発生時の対策方法
https://faq.support.nifcloud.com/faq/show/286
*1:vmwareの参考kb https://kb.vmware.com/s/article/51306?lang=ja
*2:/usr/lib/udev/rules.d/99-vmware-scsi-udev.rules による